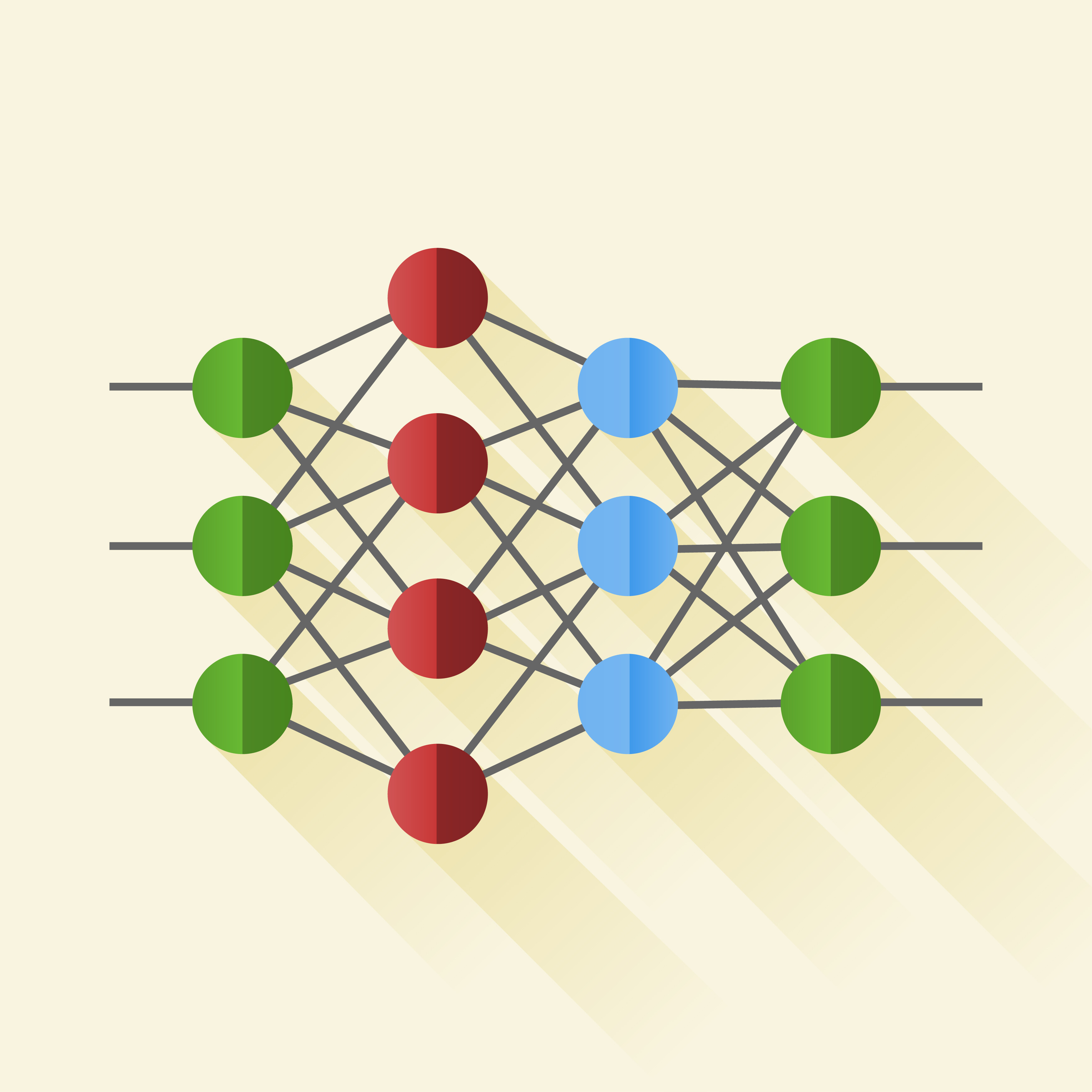
Neural Networks
A neural network (NN) is a computer program inspired by the structure of the brain. A neural network consists of many simple elements called artificial neurons, each producing a sequence of activations. The elements used in a neural network are far simpler than biological neurons. The number of elements and their interconnections are orders of magnitude fewer than the number of neurons and synapses in the human brain.
Backpropagation (BP) [Rumelhart, 1986] is the most popular supervised neural network learning algorithm. Backpropagation is organized into layers and connections between the layers. The leftmost layer is called the input layer. The rightmost, or output, layer contains the output neurons. Finally, the middle layers are called hidden layers. The goal of backpropagation is to compute the gradient (a vector of partial derivatives) of an objective function with respect to the neural network parameters. Input neurons activate through sensors perceiving the environment and other neurons activate through weighted connections from previously active neurons. Each element receives numeric inputs and transforms this input data by calculating a weighted sum over the inputs. A non-linear function is then applied to this transformation to calculate an intermediate state.
While the design of the input and output layers of a neural network is often straightforward, there is an art to the design of the hidden layers. Designing and training a neural network requires choosing the number and types of nodes, layers, learning rates, training data and test sets.
Deep learning
Recently deep learning, a new term that describes a set of algorithms that use a neural network as an underlying architecture, has generated many headlines. The earliest deep learning-like algorithms possessed multiple layers of non-linear features and can be traced back to Ivakhnenko and Lapa in 1965. They used thin but deep models with polynomial activation functions which they analyzed using statistical methods. Deep learning became more usable in recent years due to the availability of inexpensive parallel hardware (GPUs, computer clusters) and massive amounts of data.
Deep neural networks learn hierarchical layers of representation from the input to perform pattern recognition. When the problem exhibits non-linear properties, deep networks are computationally more attractive than classical neural networks. A deep network can be viewed as a program in which the functions computed by the lower-layered neurons are subroutines. These subroutines are reused many times in the computation of the final program.
Limits of deep learning
Deep learning is currently one of the main focuses of machine learning. It has led to many speculative comments about A.I. and its possible impact on the future. Although deep learning garners much attention, people fail to realize that deep learning has inherent restrictions that limit its application and effectiveness in many industries and fields. Deep learning requires human expertise and significant time to design and train.
Deep learning algorithms lack interpretability as they are not able to explain their decision-making. In mission critical applications, such as medical diagnosis, airlines, and security, people must feel confident in the reasoning behind the program, and it is difficult to trust systems that do not explain or justify their conclusions.
Another limitation is minimal changes can induce big errors. For example, in vision classification, slightly changing an image which was once correctly classified in a way that is imperceptible to the human eye can cause a deep neural network (DNN) to label the image as something else entirely.
Further examples of these limitations are presented by Patrick Henry Winston’s deep learning class, the former director of the MIT Artificial Intelligence Laboratory and an Artificial Intelligence professor at the MIT. These examples can be seen at the 44 minute mark of the following video:
Patrick H Winston MIT Deep Neural Nets Lecture
Additional examples of the limitations of deep learning are explained in a research paper from Cornell and Wyoming Universities entitled “Deep Neural Networks are Easily Fooled”.
Another interesting article is “Deep Learning Isn’t a Dangerous Magic Genie. It’s Just Math” from Oren Etzioni, a professor of Computer Science and head of the Allen Institute for Artificial Intelligence.
Smart Agents technology works with legacy software tools to overcome the limits of the legacy machine learning technologies to allow personalization, adaptability and self-learning.
